Appearance
100万亿Token证明了一件事:通用AI助手必死
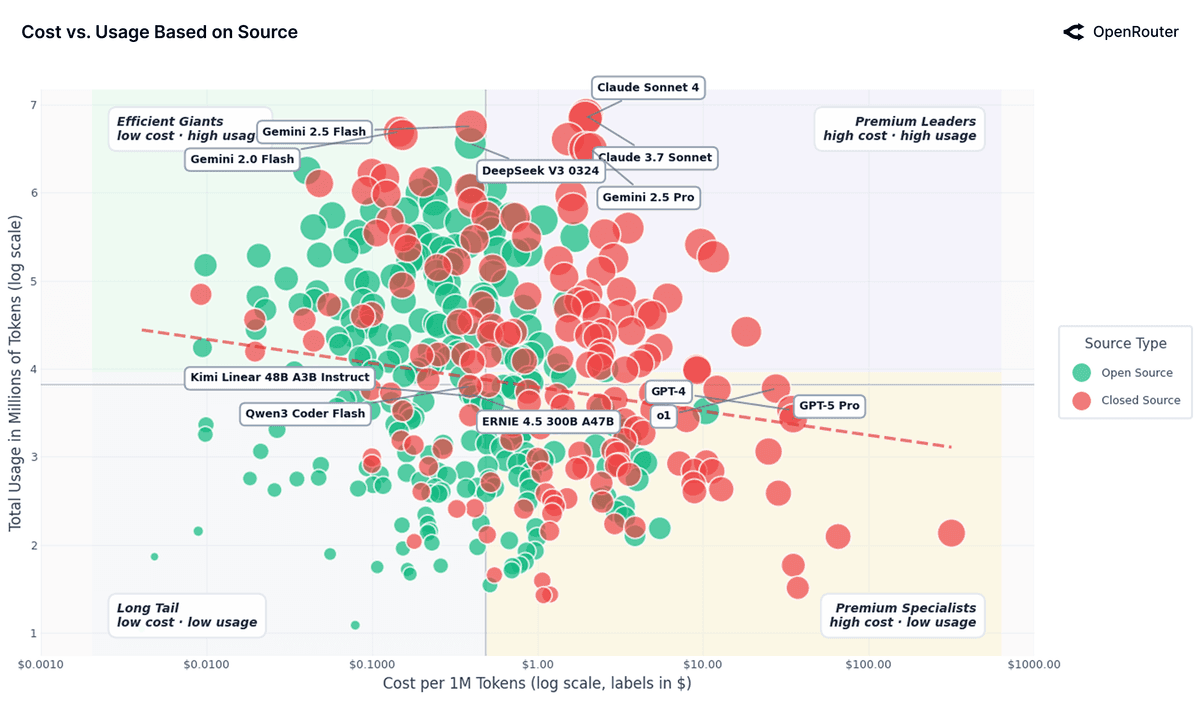
OpenRouter刚刚发布了一份重磅报告:State of AI。这不是又一份"AI很厉害"的PR稿,而是基于100万亿token真实调用数据的行为分析——相当于把全球开发者和用户"怎么用AI"的底裤扒了个干净。
报告的作者阵容值得注意:a16z的Malika Aubakirova和Anjney Midha领衔,OpenRouter团队提供数据支撑。这意味着这份报告既有顶级VC的商业视角,又有一手的平台数据。
但这份报告可能是个陷阱。
为什么?因为OpenRouter看到的是 "已经跑通的使用场景" ,而真正的机会在于 "还没被跑顺的使用场景" 。平台数据告诉你"大家在用AI做什么",但不会告诉你"大家想用AI做什么但还做不到"。
所以这篇文章从报告数据中提炼出了5个反直觉的洞察,对于AI行业从业者有非常大的参考性。
数据口径说明
- Roleplay占52%:指的是开源模型(OSS)内部的用途结构,不是全站占比
- 亚洲从13%增长到31%:说的是支出份额(spend),token份额是28.61%
- 编程从11%增长到50%+:分类数据从2025年中才稳定,更像是"2025下半年的现实"而非历史全貌
一、AI的最大增量是"可交付",不是"更聪明"
报告中有一组数据值得关注:
"Share of all tokens routed through reasoning-optimized models climbed sharply in 2025. What was effectively a negligible slice of usage in early Q1 now exceeds fifty percent."
"Average prompt tokens per request have increased roughly fourfold from around 1.5K to over 6K."
"Completions have nearly tripled from about 150 to 400 tokens."
"Tool adoption has shown a consistent upward trend throughout the year."
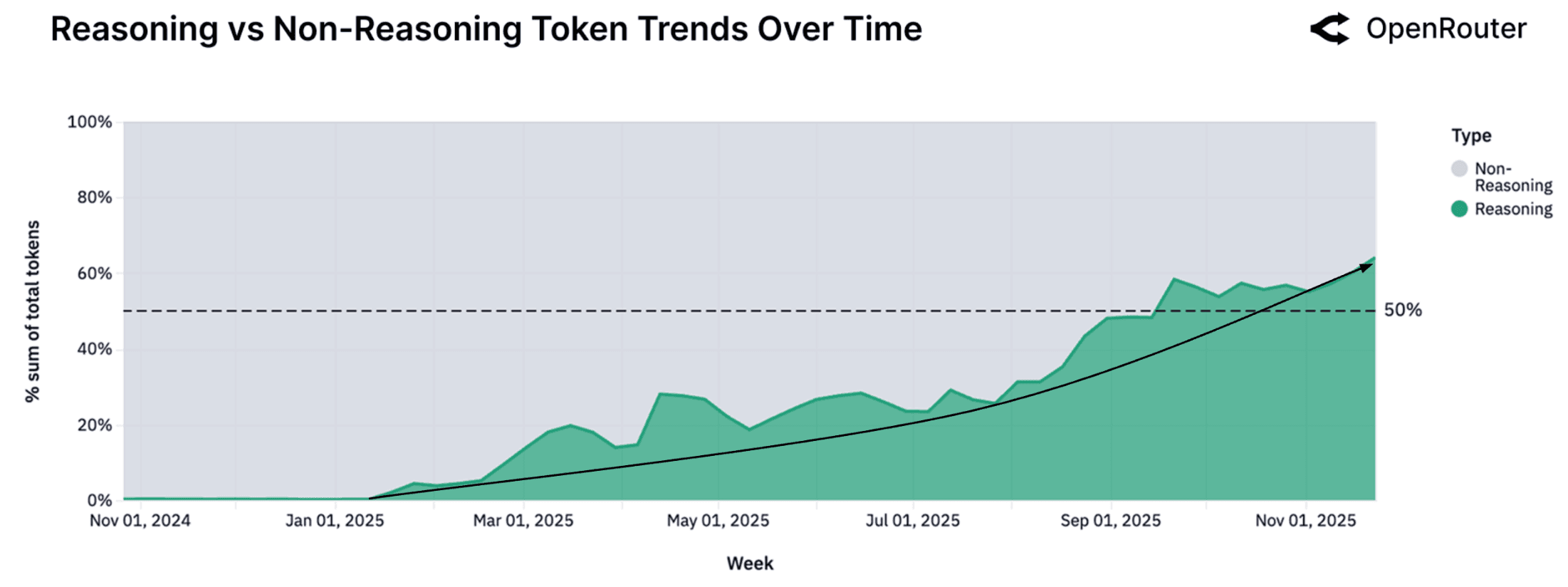
核心数据变化:
- 推理模型token占比:从年初几乎为零 → 超过50%
- prompt长度:增长近4倍(1.5K → 6K+)
- completion长度:增长3倍(150 → 400+)
- 工具调用(Tool Call):占比稳步上升
这组数据揭示了一个关键转变:用户不再只是"聊天",而是在让AI"干活"。他们愿意为"能想清楚再回答"的模型付出更多token成本,愿意给AI更复杂的任务描述和上下文。AI正在从"对话助手"变成"执行引擎"。
State of AI 2025称"推理定义了这一年"。a16z消费者AI报告的原文是这样说的:
"Bolt reported reaching $20 million in annualized revenue and 2 million registered users within its first two months."
"Lovable reported growing to $17 million in annualized revenue in its first three months."
这些爆发式增长的产品,核心卖点都不是"AI多聪明",而是"输入需求→输出可部署代码"的闭环。
有一个反直觉的关键点: 看到"推理模型占比超50%",很容易觉得应该去做"更强的推理能力"。但用户愿意为"能完成任务"付费,而不是为"推理过程更长"付费。Bolt/Lovable的成功不是因为它们用了最强的模型,而是因为它们把"成功完成一次任务"的概率做成了可量化的指标。
关键洞察
不要卖"聪明",要卖"交付"。 把产品价值从"AI能力"转向"任务完成率",设计可量化的成功指标(cost-per-success)。用户不关心你用什么模型,只关心能不能出活。
二、编程不是赛道,是AI的"分发渠道"
报告中最醒目的数据之一:
"Programming requests grew from ~11% at the start of the year to >50% in recent months."
"Programming-related prompts now average 3–4 times the token length of general-purpose prompts."
"Requests involving code understanding, debugging, and code generation routinely exceed 20K input tokens."
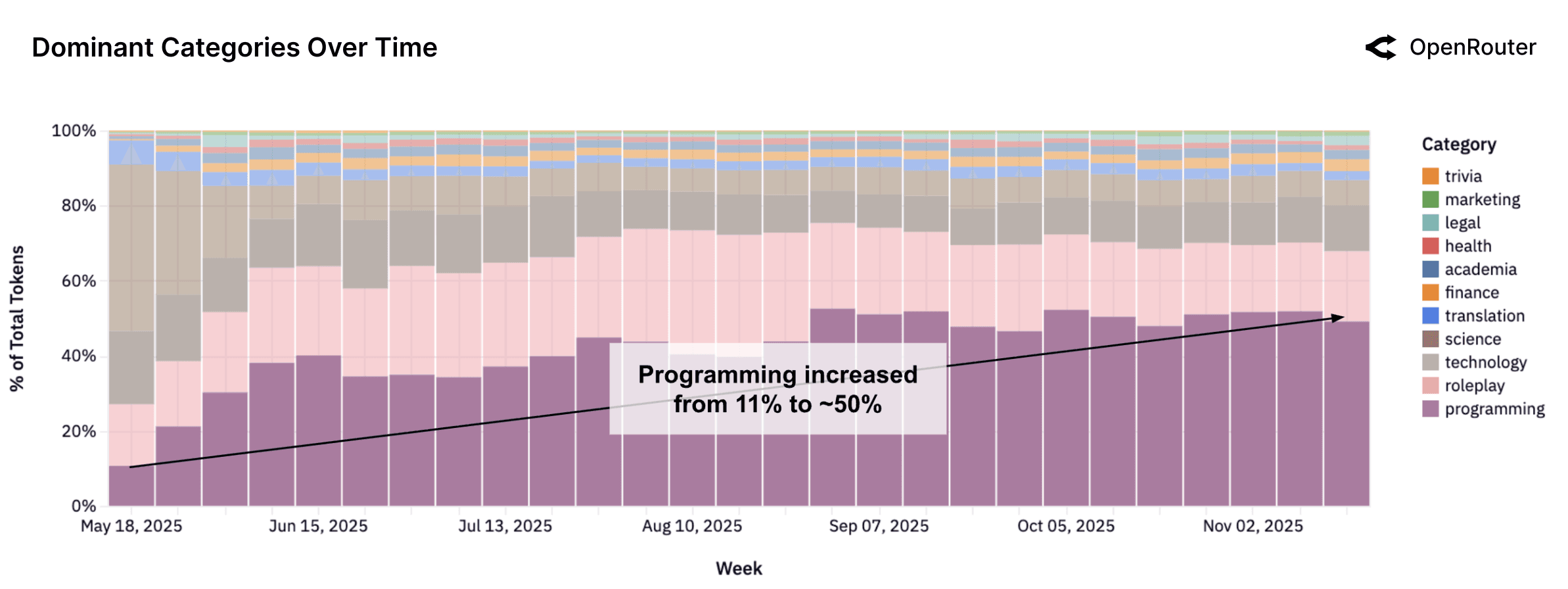
核心数据:
- 编程场景占比:从年初11% → 超过50%
- 编程类prompt长度:是普通prompt的3-4倍
- 常见输入规模:经常超过20K input tokens
看到这个数据,很多人的第一反应是"AI编程工具是最大的创业机会"。但换个角度思考就会发现:这说明编程是红海,不是蓝海。
为什么?因为"编程占比50%+"不是说"大家在用AI写代码",而是说"程序员是AI API的主要调用者"。IDE和开发工作流正在"吞掉"AI——Cursor、Claude Code、GitHub Copilot、Windsurf这些工具,本质上是把AI能力嵌入到开发者已有的工作流中。
什么叫"编程是AI的分发渠道"? 很多人习惯把ChatGPT、Claude这些独立App理解为AI的入口——用户主动打开它们来使用AI。但对于编程这个场景,开发者不会打开ChatGPT复制粘贴代码,而是直接在Cursor/VS Code里写代码时,AI已经在旁边了。关键区别是"主动打开"vs"被动触达"。就像你不会为了听歌专门打开一个"AI推荐App",而是直接在网易云/Spotify里听歌时,AI推荐已经在帮你选歌了——音乐App成了AI推荐能力的分发渠道。同理,IDE成了AI编程能力的分发渠道。谁控制了IDE,谁就控制了AI触达开发者的通道。
a16z消费者AI报告的原文:
"Cursor debuted at #41 on our web ranking."
"Bolt debuted at #48 on the list."
开发工具成为新增长极。Anthropic官方研究表明,Claude使用中coding是最大类目,占总样本36%。
竞争格局分析: 如果现在想做"通用AI编程助手",面对的竞争对手是Claude Code(Anthropic亲儿子)、Cursor(a16z重仓)、GitHub Copilot(微软+OpenAI)、Windsurf(Codeium)。这些玩家要么有模型优势,要么有分发优势,要么两者兼备。做"通用AI编程助手"= 跟分发方正面冲突。
关键洞察
编程是AI的分发渠道,不是该进的赛道。 更可能的机会是"编程+X的垂直闭环":特定行业的代码库(医疗合规代码、金融风控逻辑)、特定框架的审批与发布流程(企业内部CI/CD集成)、特定角色的工作流(非技术PM的需求→原型→代码)。
三、开源模型份额达到30%,核心不是"便宜"而是"可控"
报告中有一个反直觉的发现:
"Open-source models reached approximately 30% usage share."
"Demand is relatively price-inelastic: a 10% price reduction only increases usage by approximately 0.5-0.7%."
"Starting from a negligible base in late 2024 (weekly share as low as 1.2%), Chinese OSS models steadily gained traction...averaged approximately 13.0% of weekly token volume."

核心数据:
- 开源模型占比:达到约30%
- 价格弹性:极低,降价10%只带来0.5-0.7%的使用量增长
- 中国开源模型:从几乎为零(2024年底周份额低至1.2%)增长到13%平均份额
这说明什么?用户选开源不是为了省钱。 如果是价格驱动,降价应该带来更大的使用量增长。但数据告诉我们,用户选择开源模型的核心诉求是可控性:可定制、可部署、可规避内容限制。
State of AI 2025指出,中国扩展了开源权重生态系统,DeepSeek/Qwen在推理和编码任务上缩小差距。
有一个反直觉的关键点: 企业选开源不是为了省token费,是为了不被卡脖子。可控性的具体含义包括:SLA保障、合规审计、私域部署、路由容灾。
关键洞察
要卖的不是token单价,而是"可控性带来的确定性"。 企业级SLA(99.9%可用性保障)、合规审计能力(数据不出境、可追溯)、私域部署方案(本地化、定制化)、多模型路由与容灾(不依赖单一供应商)。
四、Roleplay不是"玩",是高黏性交互引擎的需求验证
报告中有一个容易被忽视的数据:
"Roleplay accounts for over 50% of open-source model usage."
"Internal structure is very stable: nearly 60% falls into RPG, with Writers Resources and Adult both taking significant shares."
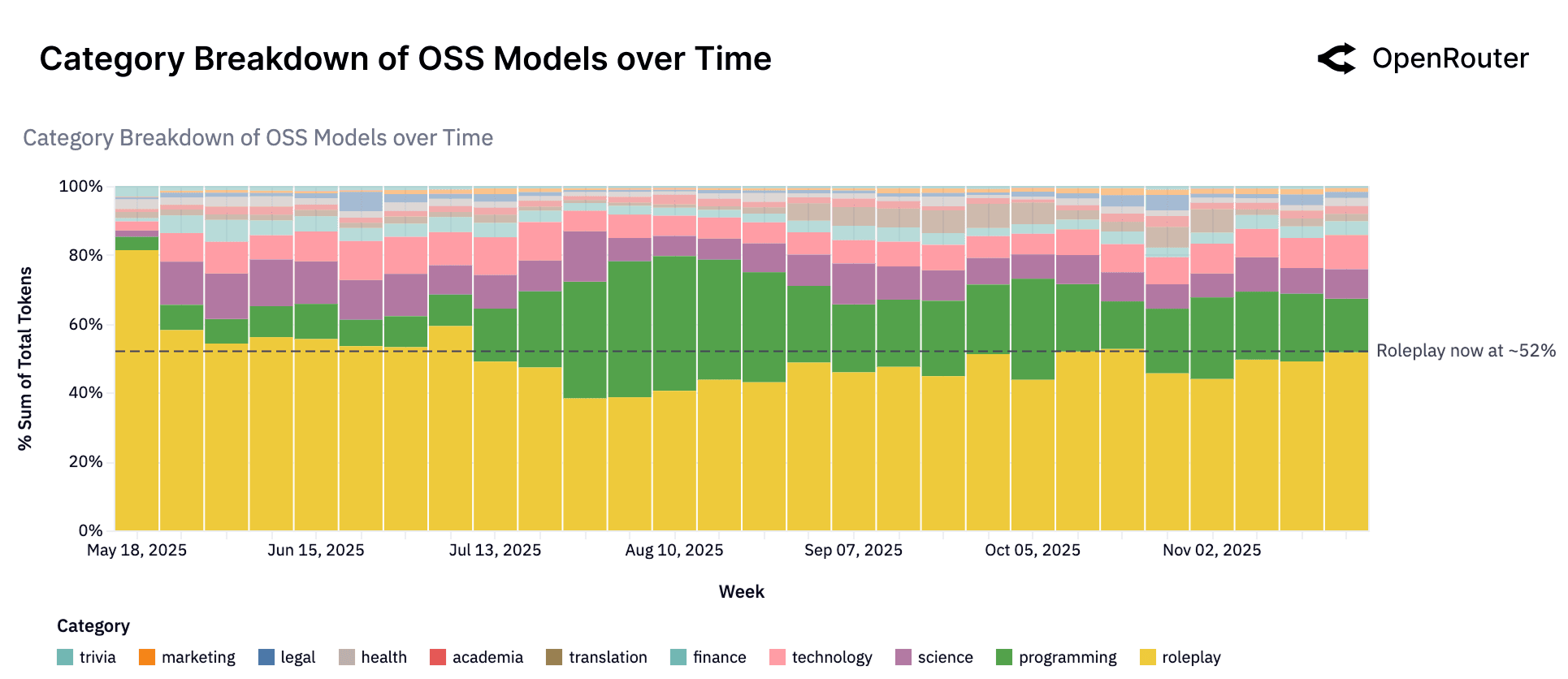
核心数据:
- Roleplay在OSS中占比:超过50%
- 内部结构:非常稳定,近60%是RPG类
- 其他类目:写作资源和成人内容各占一定份额
很多人看到这个数据会想:"Roleplay是娱乐红海,没什么创业机会。"但换个角度思考:这验证的不是"做Roleplay平台"的机会,而是"高黏性交互引擎"的技术能力。
为什么用户愿意用开源模型做Roleplay?因为商业模型有内容审核限制,用户愿意为"自由度"牺牲一定的模型能力。这说明用户对以下能力有强烈需求,强烈到愿意放弃更强的模型:人格一致性、长上下文记忆、情绪与叙事能力。
Similarweb数据显示,Character.AI平均访问时长约18分钟,pages/visit约9.52(极高的用户黏性)。a16z消费者AI报告的原文:
"Interestingly, ChatGPT 'copycat' apps represented 12% of both the mobile usage and revenue lists."
用户愿意为"陪伴"付费。
迁移方向: 这些能力完全可以迁移到合规场景——培训演练(销售话术训练、客服场景模拟、面试准备)、销售陪练(模拟客户异议处理、谈判技巧练习)、客服拟人化(有"人格"的智能客服,而非冷冰冰的FAQ机器人)、教育角色扮演(历史人物对话、语言学习场景、职业体验)。
关键洞察
把Roleplay验证的能力迁移到合规场景。 关键问题:哪些场景需要"人格一致性+长上下文+情绪叙事"但目前没有好的解决方案?
五、真正的护城河是"玻璃鞋曲线",不是榜单排名
报告中最有价值的洞察,可能是这个:
"Early user cohorts form lasting workload-model matches, creating strong lock-in effects."
"Claude 4 Sonnet and Gemini 2.5 Pro early cohorts show approximately 40% retention at month 5."
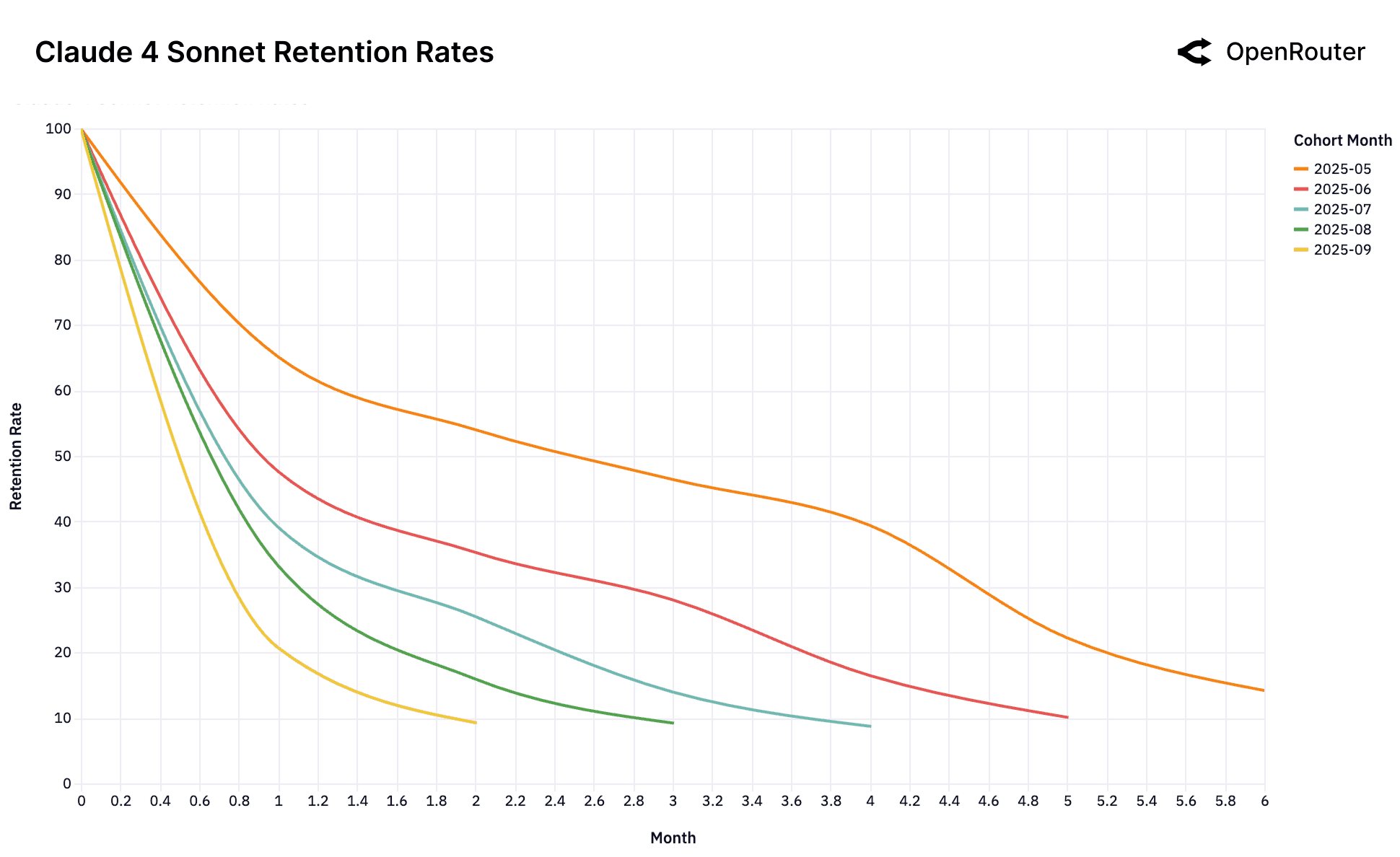
OpenRouter提出了一个关键概念:"Cinderella Glass Slipper"(灰姑娘玻璃鞋)效应。
核心发现:
- 早期cohort锁定:一旦某个模型第一次解决了某类高价值使用场景,用户就会形成强锁定
- 5个月留存约40%:Claude 4 Sonnet和Gemini 2.5 Pro的早期cohort在5个月后仍有约40%的留存(SaaS领域相当高的留存率)
- 窗口期极短:不是"谁最强谁赢",而是"谁先解决问题谁赢"
这个发现颠覆了很多人对AI竞争的理解。大家总觉得"谁的模型最强谁赢",但数据告诉我们:不是"谁最强谁赢",而是"谁先解决问题谁赢"。
a16z消费者AI报告显示,ChatGPT周活用户中<10%会访问其他大模型提供商,仅9%消费者同时为多个AI订阅付费(ChatGPT/Gemini/Claude/Cursor)。用户一旦形成习惯,就很难迁移。
有一个反直觉的关键点: AI产品的PMF = 场景-模型匹配(workload-model fit),而窗口期极短。不要等"最强模型"出来再做产品,要成为"第一个把某个痛点从不可能变成可交付"的人。
关键洞察
真正的护城河在留存曲线,不在榜单排名。 找到一个具体的、高价值的使用场景,成为第一个让这个场景"跑顺"的产品,用留存cohort数据证明锁住了那批用户。不要追"最强模型",要追"最快解决问题"。
平台数据 vs 市场机会的洞察
回到开头的问题:为什么说这份报告可能是个陷阱?
因为OpenRouter看到的是 "已经跑通的使用场景" ,而真正的机会在于 "还没被跑顺的使用场景" 。报告的分类口径是基于抽样与标签体系,且从2025年中才稳定,所以更像"趋势窗口"而非历史全貌。
提炼并解读报告的几个关键数据:
| 平台数据说的 | 应该怎么理解 |
|---|---|
| 编程占50%+ | 编程是红海——Cursor/Copilot已经把AI"内置"到开发者每天必用的工具里了。但"编程+垂直行业"是蓝海,比如医疗合规代码、金融风控逻辑这些需要领域知识的场景 |
| Roleplay占OSS 52% | 高黏性交互能力已验证——用户愿意为"人格一致性+长上下文+情绪叙事"放弃更强的模型。这些能力可以迁移到培训演练、销售陪练、拟人化客服等合规场景 |
| 开源占30% | 可控性需求已验证——企业选开源不是为了省钱(价格弹性极低),而是为了SLA保障、合规审计、私域部署。卖确定性而非便宜 |
| 推理模型>50% | Agent化是方向——用户愿意付更多token成本让AI"想清楚再回答"。但卖"交付"而非"自主",Bolt/Lovable的成功是"任务完成率"而非"推理能力" |
| 亚洲增长翻倍 | 中国用户大量使用国内平台(豆包、Kimi、智谱),OpenRouter的中文只占4.95%。出海本地化是机会 |
| 法律/金融/健康分散 | 垂直领域优化不足——这些领域需要合规、数据、信任的壁垒,但一旦建立就很难被替代 |
从数据中提炼的三个验证维度
基于以上5个洞察,可以提炼出三个验证AI产品的关键维度:
维度一:交付周期
产品能不能在短周期内让用户完成一个具体的、可量化的任务?不是"AI能力演示",而是"任务完成";不是"对话更流畅",而是"工作被做完"。参考数据:Bolt 2个月2000万ARR,核心是"需求→可部署代码"的闭环。
维度二:成功成本(cost-per-success)
能不能定义一个"成功完成任务"的指标,并计算每次成功的成本?不是"用户满意度",而是"任务完成率";不是"token消耗",而是"每次成功交付的成本"。这个指标决定了定价能力和利润空间。
维度三:留存cohort
早期用户在3-6个月后还在用产品吗?参考基准:Claude/Gemini早期cohort 5个月留存约40%。如果留存低于20%,说明没有形成"玻璃鞋效应"。高留存 = 解决了一个真实的、持续的痛点。
通用AI助手为什么必死
回到标题:为什么说"通用AI助手必死"?
因为100万亿token的数据揭示了三个核心原因:
原因一:用户要的是"交付",通用助手交付不了
推理模型占比从年初几乎为零飙升到超过50%,prompt长度增长4倍(1.5K→6K+),completion长度增长3倍(150→400+)。用户愿意付更多token成本,是为了"任务完成",不是为了"对话更流畅"。Bolt 2个月2000万ARR、Lovable 3个月1700万ARR,核心卖点是"输入需求→输出可部署代码"的闭环。通用AI助手什么都能聊,但什么都交付不了。
原因二:AI的分发入口已经被巨头锁定,通用助手没有入口
编程占50%+,但这不是说"大家在用AI写代码",而是说"IDE成了AI触达开发者的通道"。Cursor、Claude Code、GitHub Copilot、Windsurf已经把AI能力"内置"到开发者每天必用的工具里了。用户不会单独打开一个"通用AI"来写代码,而是直接在IDE里用AI。做"通用AI编程助手"= 跟分发方正面冲突。
原因三:窗口期已经关闭,通用助手没有机会了
Claude 4 Sonnet和Gemini 2.5 Pro的早期cohort在5个月后仍有约40%的留存。ChatGPT周活用户中<10%会访问其他大模型提供商,仅9%消费者同时为多个AI订阅付费。玻璃鞋效应决定谁能活下来——不是"谁最强谁赢",而是"谁先解决问题谁赢"。通用助手没有"第一个解决某个具体问题"的机会,因为它什么都做一点,什么都不精。
所以,"通用AI助手"——那种什么都能做一点、但什么都做不精的产品——在这个市场里没有生存空间。用户要的是"能交付",不是"能聊天";要的是"解决我的问题",不是"展示AI的能力"。
数据来源与参考链接
主数据源
| 报告名称 | 发布机构 | 链接 |
|---|---|---|
| State of AI | OpenRouter | openrouter.ai/state-of-ai |
交叉验证数据源
| 报告名称 | 发布机构 | 核心数据 | 链接 |
|---|---|---|---|
| State of AI Report 2025 | Air Street Capital | 44%企业付费、$530K平均合同 | stateof.ai |
| 100 Gen AI Apps | a16z | 消费者AI使用行为、留存数据 | a16z.com |
| Octoverse 2025 | GitHub | 80%新开发者用Copilot | github.blog |
| AI Index 2025 | Stanford HAI | 开闭源差距1.7% | hai.stanford.edu |
其他引用:Anthropic官方研究(Claude使用中coding占36%)、Similarweb(Character.AI访问时长18分钟)、Cursor官网(财富500强一半采用)
关于本报告
作者:Heliki AI 社区 发布日期:2025-12-28 版本:v1.0
本报告基于公开数据进行分析解读,观点仅供参考,不构成投资建议。数据截止日期以各原始报告发布时间为准。
引用格式:Heliki AI 社区. (2025). 100万亿Token证明了一件事:通用AI助手必死. https://www.heliki.com/learn/reports/openrouter-state-of-ai-2025