Appearance
DeepSeek-OCR:用视觉压缩上下文,一张图顶一千词
—— DeepSeek 研究团队技术报告
内容摘要
当前大语言模型处理长文本时面临计算成本随序列长度平方增长的问题。DeepSeek团队提出了一个反直觉的解决方案:与其用更多文本token,不如把文本渲染成图像,用vision token来压缩表示。
这个想法很简单:一张包含1000个字的文档图片,用几百个vision token就能表示,而如果直接用文字输入则需要1000多个text token。DeepSeek-OCR就是为了验证这个"上下文光学压缩"思路而设计的。
核心组件是DeepEncoder,一个专为高分辨率输入设计的视觉编码器。它通过窗口注意力和全局注意力串联,配合16倍卷积压缩器,在保持低激活内存的同时实现高压缩比。解码器使用DeepSeek3B-MoE,只有570M激活参数。
实验结果很有意思:压缩比在10倍以内时,OCR解码精度能达到97%,接近无损压缩;即使压缩20倍,准确率仍有60%左右。这意味着把历史对话渲染成图像,可以用10倍更少的token存储,而且越早的对话可以压缩得越狠,自然形成"遗忘机制"。
实用价值方面,DeepSeek-OCR在OmniDocBench上只用100个vision token就超过了GOT-OCR2.0的256 token版本,用不到800个token超过了MinerU2.0的6000多token。单张A100-40G每天能处理20万页文档,适合大规模LLM训练数据生成。
核心发现
10倍压缩接近无损,20倍仍可用
在Fox基准测试上,当文本token数量在vision token的10倍以内时(即压缩比小于10倍),模型的OCR解码精度可以达到96-97%。这个结果表明,对于最近的对话历史,可以用光学压缩实现接近无损的token节省。当压缩比提升到20倍时,精度降到约60%,虽然不能完全还原,但核心信息仍然保留。这种渐进式的精度下降,正好可以模拟人类记忆的遗忘曲线。

上图展示了DeepSeek-OCR的两个关键性能指标:
左图(Fox基准压缩测试):展示了不同压缩比下的OCR精度。可以看到64个vision token(左侧柱状图)和100个vision token(右侧柱状图)在不同压缩倍数下的表现。当压缩比为5-10倍时,准确率保持在96-98%的高水平;15倍压缩时仍有85-91%;即使20倍压缩,也能保持约60%的可用精度。这条性能曲线为实际应用提供了清晰的设计指导。
右图(OmniDocBench性能对比):横轴是平均每页使用的vision token数量,纵轴是编辑距离(越小越好)。DeepSeek-OCR的多个版本(Tiny/Small/Base/Large)形成了一条帕累托前沿,在token效率和准确性之间达到最佳平衡。特别是Small版本(100 token)就能超越GOT-OCR2.0(256 token),Base版本(约256 token)接近dots.ocr(3949 token)的性能。
DeepEncoder:低激活高压缩的关键
传统的视觉编码器在处理高分辨率图像时面临两难:用小patch会产生大量token导致全局注意力激活爆炸;用大patch虽然token少但会丢失细节。DeepEncoder通过串联架构解决了这个问题:前半部分是80M的SAM-base,用窗口注意力处理4096个patch,激活可控;然后通过16倍压缩降到256个token;后半部分是300M的CLIP-large,用全局注意力提取高级特征。这样既保证了细节感知,又控制住了计算成本。
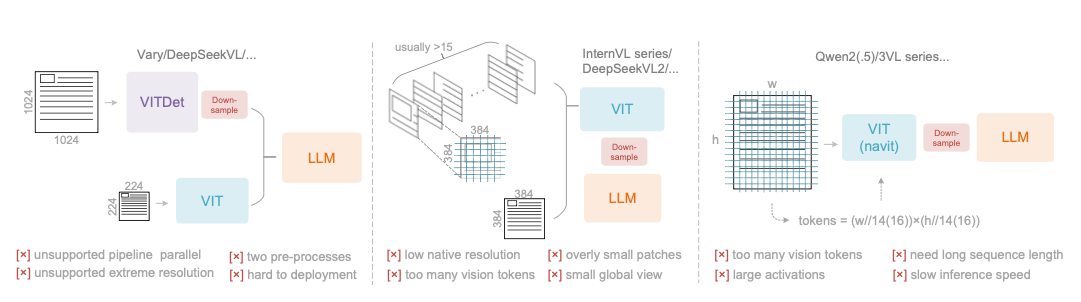
上图对比了三种主流VLM编码器架构的问题:
双塔架构(Vary/DeepSeekVL):需要双重图像预处理,一个低分辨率塔(224×224)加一个高分辨率塔(1024×1024),无法进行流水线并行,部署复杂。
瓦片式(InternVL系列):原生分辨率太低(通常<512),导致大图被切成过多小块,产生大量vision token(usually>15个瓦片),且全局视野受损。
自适应分辨率(Qwen2-VL系列):虽然支持动态分辨率,但patch太小导致激活内存巨大,需要极长序列训练,推理速度慢。
DeepEncoder的创新在于用串联架构解决了这些问题。
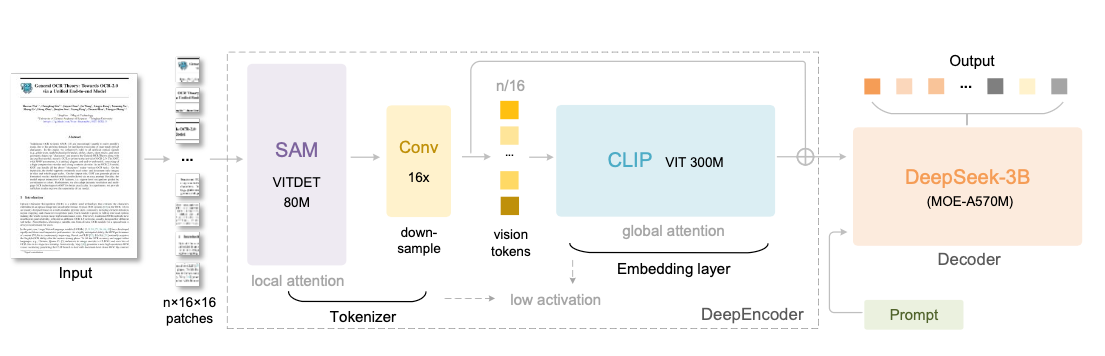
这张架构图清晰展示了DeepSeek-OCR的完整数据流:
- 输入图像被分割成n×16×16的patches
- SAM(80M参数)用窗口注意力处理,保持低激活
- 16倍卷积下采样器大幅压缩token数量
- CLIP VIT(300M参数)用全局注意力提取高级特征
- 输出vision tokens送入DeepSeek-3B-MoE解码器
- 结合用户提示词生成最终结果
整个流程的关键是"先多后少":在计算廉价的窗口注意力阶段处理大量token,在计算昂贵的全局注意力阶段只处理少量token。
多分辨率支持灵活适配
DeepSeek-OCR支持从512×512(64 token)到1280×1280(400 token)的多种原生分辨率,还支持Gundam动态分辨率模式(多个局部视图加一个全局视图)。这种设计让同一个模型可以根据内容复杂度灵活调整token数量:简单文档用Tiny模式64个token就够,复杂报纸需要Gundam模式800个token。训练时所有分辨率模式同时训练,实现一个模型多种用法。

这张图展示了六种分辨率模式的设计:
- Tiny(512×512, 64 tokens):适合简单文档和幻灯片
- Small(640×640, 100 tokens):适合一般文档
- Base(1024×1024, 256 tokens):适合复杂文档
- Large(1280×1280, 400 tokens):适合高质量需求
- Gundam(n×640+1024, n×100+256 tokens):适合长文档
- Gundam-M(n×1024+1280, n×256+400 tokens):适合超长文档
Tiny和Small模式使用resize保持宽高比,Base和Large使用padding保留原始比例,Gundam系列使用瓦片+全局视图的混合策略。所有模式通过位置编码插值统一在同一个模型中。
生产级数据生成能力
在实际部署中,使用20个节点(每节点8张A100-40G),DeepSeek-OCR每天可以处理3300万页文档。这个吞吐量对于LLM和VLM的预训练数据生成至关重要。而且由于token压缩比高,生成的训练数据更紧凑,可以减少下游模型训练时的计算成本。
深入理解:这到底是什么模型?
是OCR模型,也是视觉-语言模型
很多人第一次看到DeepSeek-OCR这个名字,会简单认为这就是一个文字识别工具,类似PaddleOCR或Tesseract。这种理解既对也不对。
从功能上看,DeepSeek-OCR确实能完成传统OCR的所有任务:识别图片中的文字、提取文档内容、处理多语言文本。但它的本质是一个完整的视觉-语言多模态模型(Vision-Language Model, VLM),只是训练任务聚焦在OCR领域。
传统OCR模型和VLM的核心区别在于:
传统OCR模型的工作方式:
- 检测模块:找出图片中所有的文字区域(bounding box)
- 识别模块:对每个文字区域进行字符识别
- 后处理:把识别结果按空间位置组装成文本
这是一个典型的"检测-识别"两阶段流程,每个阶段都是独立的模型,最后靠后处理规则拼接结果。这种架构的问题是:模块之间割裂,无法理解上下文,容易出现识别错误后无法纠正的情况。
DeepSeek-OCR作为VLM的工作方式:
- 视觉编码器(DeepEncoder):将整张图片编码成一组vision tokens
- 语言解码器(DeepSeek-3B-MoE):基于vision tokens生成文本输出
- 端到端训练:通过"看图说话"的方式学习OCR能力
这是一个统一的生成式架构,模型"看懂"整张图片后,用自然语言生成的方式输出结果。这种架构的优势是可以利用上下文纠错、理解版面语义、甚至进行推理。
举个例子:如果图片中有一行字是"今天气温25度",传统OCR可能把"温"识别成"湿",因为它只看单个字的图像特征。但DeepSeek-OCR作为VLM,它会理解"今天气__25度"这个上下文,推断出应该是"温"而不是"湿"。
视觉模型的新范式:压缩而非理解
更深层次的创新在于,DeepSeek-OCR重新定义了视觉模态在多模态模型中的角色。
传统VLM的设计哲学是"让AI像人一样看世界"。我们训练模型识别物体、理解场景、回答视觉问答。视觉编码器的任务是"理解"图像内容,提取语义特征。
但DeepSeek-OCR提出了另一个视角:视觉模态不只是用来"看"的,还可以用来"存"的。图像是一种高度压缩的信息载体,一张1024×1024的图片只需要256个vision token就能表示,但如果把图片中的文字都转成文本token,可能需要2000-3000个token。
这个发现的意义在于:我们可以把视觉编码器当作一个"压缩器",专门用来压缩文本信息。这不是传统意义上的OCR,而是一种新的上下文管理范式。
论文中有一个特别有意思的实验:他们把同样的文字内容分别用两种方式输入给模型:
- 方式A:直接输入纯文本,占用1000个text token
- 方式B:把文字渲染成图片,再用DeepEncoder编码成100个vision token
结果发现,方式B在保持90%+准确率的同时,只用了方式A十分之一的token。这说明什么?说明对于"已经看过的内容",我们不需要保留完整的文本形式,用压缩后的视觉形式存储就够了。
这就是为什么论文标题不是"DeepSeek-OCR: A Better OCR Model",而是"Contexts Optical Compression"(上下文光学压缩)。OCR只是实现压缩的手段和验证方式,真正的目标是探索用视觉模态压缩语言信息的可能性。
数据工程:OCR能力的基础
OCR 1.0:文字识别的规模化
DeepSeek团队收集了3000万页多语言PDF文档,覆盖约100种语言。这个规模在开源OCR数据集中已经相当可观。更重要的是数据标注的策略。

上图展示了精细标注的数据格式:每段文字都被标注了坐标位置和类型(标题、正文、图表等),所有坐标归一化到1000个bins。这种标注方式让模型不仅能识别文字,还能理解文档结构。
数据分为两类:
粗标注(3000万页全量): 使用fitz库直接从PDF提取文字,质量参差不齐但规模大。主要用于教会模型识别各种语言的字符,特别是小语种。训练时使用"Free OCR"这样的简单提示词,告诉模型只需要输出纯文本。
精细标注(中英各200万页,小语种60万页): 使用先进的版面分析模型(PP-DocLayout)和OCR模型(MinerU、GOT-OCR2.0)构建检测和识别交错的数据。每段文字前都标注了bbox坐标和类型。训练时使用"Convert the document to markdown"这样的复杂提示词,要求模型输出结构化结果。
小语种数据的标注特别有意思,采用了"模型飞轮"策略:
- 用版面模型切出文字小块(版面模型的泛化性较好)
- 用fitz提取的粗标注数据训练一个GOT-OCR2.0
- 用训练好的模型给小块图像打标签
- 把标签结果组装成完整的精细标注
这种方式用少量监督信号(版面+粗文本)生成了大量高质量数据。
OCR 2.0:图表和公式的结构化
传统OCR只处理纯文本,但真实文档中大量的信息是用图表、公式、几何图形来表达的。DeepSeek-OCR的OCR 2.0数据就是为了处理这些结构化内容。
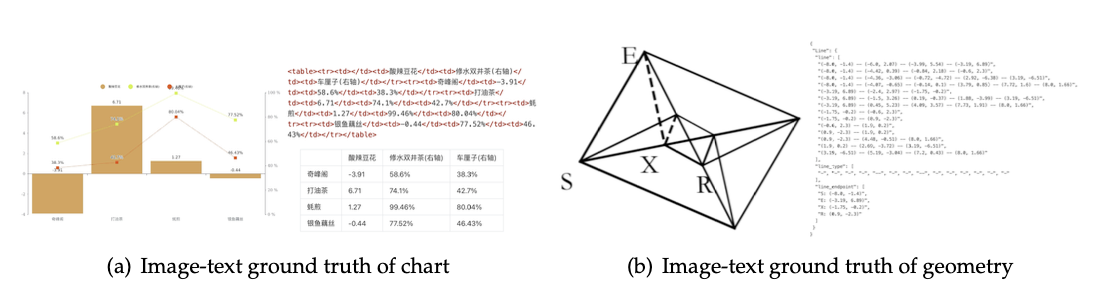
上图展示了两类OCR 2.0数据的标注方式:
图表数据(1000万张): 使用pyecharts和matplotlib渲染常见的折线图、柱状图、饼图和组合图。标注格式是HTML表格而非字典,因为HTML表格更紧凑,能节省token。例如一个三列五行的表格,用HTML表示可能只需要几十个token,用字典格式可能需要上百个。
几何图形(100万张): 参考Slow Perception的生成方法,每条线段用4个参数编码(起点x、起点y、终点x、终点y)。标注格式是字典,包含线段列表、端点坐标、线段类型等键值对。还引入了平移不变性数据增强:同一个几何图形在图片不同位置,对应的标注都是相对于中心坐标系的,这样可以让模型学到平移不变的几何理解能力。
化学式数据(500万张): 从PubChem数据库获取SMILES格式的分子式,用RDKit渲染成图像。SMILES是一种用ASCII字符串表示分子结构的方法,例如"CC(=O)O"表示乙酸。这类数据让模型具备了化学文档解析能力。
深度解析能力的实战应用
OCR 2.0数据带来的最实用的功能是"深度解析"。这个功能可以通过二次模型调用实现:
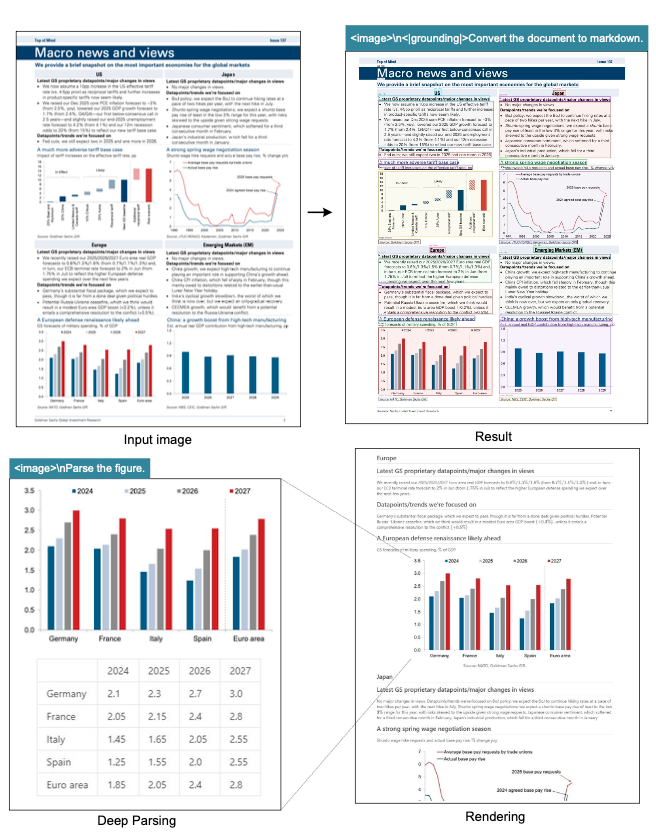
第一步,用grounding模式识别文档:
<image>\n<|grounding|>Convert the document to markdown.模型输出带坐标的结构化文档,把图表的位置都标出来。
第二步,对检测到的图表区域单独解析:
<image>\nParse the figure.模型直接输出HTML表格,把图表中的数据完整提取出来。这对于需要处理大量财报、研究报告的场景特别有价值。

同样的流程也适用于自然图像。文档中的照片会被识别出来,然后模型可以为每张照片生成详细的caption。这种能力来自于训练数据中包含的20%通用视觉数据。
虽然DeepSeek-OCR不是通用VLM,但保留通用视觉接口的设计很聪明:一方面增强了实用性,另一方面为未来的研究提供了基础。研究者可以在DeepSeek-OCR的基础上继续训练通用视觉能力,而不需要从头开始。
训练策略:两阶段流水线
DeepSeek-OCR的训练分为两个阶段,这个设计很巧妙。
第一阶段:独立训练DeepEncoder
用一个小的语言模型(论文中用的是500M级别的模型)做解码器,在所有OCR数据加100M通用图像数据上训练DeepEncoder。这个阶段的目的是让视觉编码器学会把图像压缩成有用的vision token。
训练参数:
- Batch size: 1280
- 学习率: 5e-5(AdamW优化器,cosine调度器)
- 序列长度: 4096
- 训练轮数: 2 epochs
- 数据:OCR 1.0 + OCR 2.0 + 100M通用图像
这个阶段结束后,DeepEncoder已经具备了基本的视觉特征提取能力。
第二阶段:联合训练完整VLM
把DeepEncoder和DeepSeek-3B-MoE拼接起来,用完整的训练数据继续训练。这个阶段的参数配置很有意思:
使用4阶段流水线并行(PP=4):
- PP0:SAM + 卷积压缩器(冻结参数,只做推理)
- PP1:CLIP(训练)
- PP2:DeepSeek-3B的前6层(训练)
- PP3:DeepSeek-3B的后6层(训练)
这样做的好处是把SAM当作固定的"视觉分词器",只训练后续的语义理解部分。既保持了训练稳定性,又减少了计算量。
硬件配置:20节点×8卡A100-40G,数据并行DP=40,全局batch size=640。
训练速度:
- 纯文本数据:90B tokens/天
- 多模态数据:70B tokens/天
数据配比:OCR 70%,通用视觉20%,纯文本10%。纯文本数据的作用是保持语言能力,避免模型过度拟合视觉任务导致语言能力退化。
对行业的指导意义
重新思考上下文窗口的设计
当前所有大语言模型都在拼命扩展上下文窗口,从最早的2k到现在的128k甚至1M。但这条路越走越难:
- 注意力计算复杂度是O(n²),序列长度翻倍,计算量翻四倍
- KV缓存占用大量显存,限制了batch size和吞吐量
- 长上下文训练需要海量数据和算力
DeepSeek-OCR提供了另一个思路:不是让模型处理更长的文本,而是用视觉压缩减少token数量。
具体应用场景:
多轮对话系统: 现在的聊天机器人通常只能记住最近几十轮对话,因为历史对话占用太多token。用DeepSeek-OCR的方法,可以把超过N轮的历史对话渲染成图片,压缩到原来的十分之一。这样同样的上下文窗口可以容纳10倍的对话历史。
文档问答系统: 传统RAG(检索增强生成)的方式是把相关文档切片,检索topk片段拼接到prompt中。但切片会破坏上下文完整性,拼接受限于上下文长度。用光学压缩,可以把整个文档压缩后放入上下文,让模型"看"完整文档而不是片段。
代码补全和review: 程序员用IDE写代码时,通常需要参考多个文件的代码。传统方法是把所有相关文件的代码都放入上下文,但这会迅速超过token限制。用视觉压缩,可以把"不太相关但需要看"的代码渲染成图片,只保留"当前编辑的"代码用文本形式,极大扩展了AI能参考的代码范围。
遗忘机制:从bug到feature
论文最后的Discussion部分提到了一个非常深刻的观点:渐进式降低历史上下文的分辨率,本质上是一种遗忘机制。
人类的记忆遗忘曲线是这样的:
- 刚发生的事情记得清清楚楚(高保真)
- 几天前的事情开始模糊(有损压缩)
- 几个月前的事情只记得大概(高度压缩)
- 几年前的事情可能完全忘记(丢弃)
DeepSeek-OCR的多分辨率模式完美对应了这个曲线:
- 最近10轮对话:纯文本,完全保真
- 10-100轮对话:Large模式,400 token压缩
- 100-500轮对话:Base模式,256 token压缩
- 500-1000轮对话:Small模式,100 token压缩
- 1000轮以上:Tiny模式,64 token压缩或直接丢弃
这种设计不是系统的缺陷,而是特性。因为对于绝大多数任务,我们并不需要精确记住所有历史细节,只需要保留重要的脉络。就像人类不可能记住每天吃的每顿饭,但会记住重要的聚餐和特殊的味道。
这个机制对于构建长期运行的AI助手特别有价值。设想一个陪伴用户一整年的AI助手,如果要完整记住365天的所有对话,成本是天文数字。但如果采用渐进式遗忘,成本可以控制在合理范围,同时保持对重要事件的记忆。
多模态模型的新方向:专用而非通用
DeepSeek-OCR的定位很清晰:它是一个专注于OCR和文档理解的VLM,而不是追求通用的"什么都能做"的模型。
这个定位带来的启发是:多模态模型不一定要走通用路线,专用模型可能更有价值。
原因有三:
1. 数据效率更高
通用VLM需要大量不同类型的数据:图像字幕、视觉问答、物体检测、OCR、图表理解等等。但每种任务的数据分布差异很大,模型需要很大的容量才能同时学好所有任务。
专用模型只需要聚焦某一类任务的数据,可以用更小的模型达到更好的效果。DeepSeek-OCR只有3B参数(激活570M),但在OCR任务上超过了很多更大的通用VLM。
2. 推理效率更高
通用模型为了应对各种任务,必须保持很大的容量和激活参数。但实际使用时,90%的场景可能只需要其中一种能力。
专用模型可以针对特定任务优化架构和参数,获得更快的推理速度和更低的成本。这对于需要大规模部署的应用特别重要。
3. 可组合性更强
与其训练一个巨大的全能模型,不如训练多个专精的小模型,根据任务动态组合。例如:
- 文档理解用DeepSeek-OCR
- 图像生成用DALL-E
- 视频理解用专门的视频模型
- 3D场景理解用专门的3D模型
每个模型都在自己擅长的领域做到最好,通过统一的接口组合使用。这种架构比一个巨型模型更灵活、更好维护、成本也更可控。
DeepSeek-OCR保留20%通用视觉数据的设计很聪明:既保持了专注性,又留下了扩展接口。如果未来需要增强某些通用能力,可以在这个基础上继续训练,而不需要重新开始。
OCR技术的范式转变
传统OCR是一个相对成熟的领域,Tesseract、PaddleOCR等开源工具已经能满足大部分需求。DeepSeek-OCR带来的不是精度的小幅提升,而是范式的根本改变。
从"检测+识别"到"端到端生成"
传统OCR的流程是:先检测文字区域,再识别每个区域的字符,最后拼接成文本。这个流程的问题是:
- 检测错误会导致漏识别
- 识别错误无法通过上下文纠正
- 版面理解需要额外的后处理
DeepSeek-OCR的端到端生成方式,让模型可以:
- 利用上下文纠正识别错误
- 理解文档语义而不只是字符
- 直接输出结构化结果(markdown、HTML等)
从"提取文字"到"理解文档"
更深层的变化是任务定义的改变。传统OCR的目标是"把图片上的字变成文本",而DeepSeek-OCR的目标是"理解文档内容并生成结构化表示"。
这意味着:
- 不只是识别文字,还要识别表格、图表、公式
- 不只是输出纯文本,还要保留文档结构
- 不只是做识别,还可以做转换(图表转表格)、推理(公式计算)等
这种能力对于文档智能化处理的意义重大。例如:
- 自动化财报分析:不只提取数字,还要理解图表关系
- 科研文献处理:识别公式并转换为可编辑格式
- 合同审查:理解条款结构而不只是提取文字
局限性与未来方向
论文很诚实地指出,当前的DeepSeek-OCR还只是"初步探索"(initial investigation),有很多需要改进的地方:
1. 压缩比的边界还不清楚
虽然论文证明了10倍压缩接近无损,20倍还能保持60%准确率,但这是在OCR任务上的结论。对于真正的长上下文应用(比如历史对话压缩),这个边界可能不同。
需要进一步研究:
- 不同类型内容的最优压缩比(对话、代码、文档各不相同)
- 压缩后的信息损失对下游任务的影响
- 如何动态选择压缩比
2. 数字-光学混合的预训练还未验证
论文中的实验都是先渲染成图片,再用DeepEncoder编码,最后用语言模型解码。但真正的应用场景应该是混合输入:一部分是纯文本token,一部分是压缩后的视觉token。
这需要重新设计预训练策略:
- 让模型从一开始就适应混合输入
- 学习何时该压缩、何时该保留文本
- 在两种模态之间自由切换
3. 遗忘机制的可控性
渐进式降低分辨率可以模拟遗忘,但这是一种"被动遗忘"——所有内容都按时间线性衰减。真正的智能遗忘应该是"主动遗忘"——重要的信息保留高分辨率,不重要的快速降级。
这需要引入重要性评估机制:
- 根据内容重要性动态选择压缩比
- 允许用户标记"重要对话"防止被压缩
- 根据后续引用频率调整历史内容的分辨率
4. 计算成本的权衡
虽然vision token数量减少了,但视觉编码器本身也需要计算。对于简单的纯文本对话,渲染图片再编码可能比直接用文本token更慢。
需要明确什么场景下用光学压缩是划算的:
- 多长的文本才值得压缩?
- 视觉编码的成本如何分摊?
- 能否设计更轻量的编码器?
总结与思考
DeepSeek-OCR不只是一个OCR模型,它提出了一种全新的思维方式:把视觉模态当作文本信息的压缩和存储媒介。
这个思路的深层含义是,多模态融合不一定是"让AI同时理解图像和文本",也可以是"用最高效的模态表示不同的信息"。文字不一定要用文本token,图像不一定要用来"看",音频不一定要用来"听"。每种模态都是一种信息编码方式,应该根据任务选择最合适的编码。
从工程角度看,DeepSeek-OCR已经是一个非常实用的工具:
- 每天处理20万页文档的生产能力
- 在主流benchmark上超越现有最佳方案
- 完整开源,可以直接用于LLM数据生成
从研究角度看,它开辟了几个值得深入的方向:
- 上下文光学压缩的理论边界
- 多模态信息的最优表示
- 遗忘机制在AI系统中的作用
最重要的是,这篇工作提醒我们:不要被既有范式束缚。当所有人都在拼命扩展上下文窗口时,DeepSeek选择了压缩;当所有人都在训练通用VLM时,DeepSeek选择了专用。有时候,换一个角度看问题,答案就在那里。
DeepSeek-OCR的核心突破在于: 重新定义了视觉和语言模态的关系——视觉不仅是感知世界的方式,也是压缩和存储文本信息的高效媒介。这为解决LLM的长上下文问题开辟了全新路径。