Appearance
智能体 RAG 模式

点击上方图片可观看原课程视频。
本节全面介绍“智能体检索增强生成(Agentic RAG)”这一新兴范式:大型语言模型(LLM)在执行任务时,会自主规划下一步动作,并在多轮循环中调用检索工具与函数,直到得到满意答案。相比传统的“先检索再阅读”,Agentic RAG 更像是“生成—调用工具—再生成”的闭环系统,能够不断评估结果、修正查询并追加工具调用,从而保证输出质量。
引言
本节将围绕以下问题展开:
- 理解 Agentic RAG:认识这一范式如何让 LLM 在引入外部数据源的同时保持自主规划能力。
- 掌握迭代式 Maker-Checker 流程:了解模型如何在多轮调用中穿插工具执行与结构化输出,并借此提升正确率、处理格式错误的查询。
- 探索实际应用:识别 Agentic RAG 最闪光的场景,例如对正确性要求极高的任务、复杂数据库交互或跨多步骤的长流程。
学习目标
完成本节后,你将能够:
- 定义 Agentic RAG:理解其与传统 RAG 的区别,以及为何需要“自主规划+检索”的组合。
- 把握迭代式循环:熟悉模型在循环中如何调度工具、结构化输出,并在必要时反复调整。
- 掌控推理过程:理解系统如何自行决定解决问题的路径,而非完全依赖预设流程。
- 分析典型工作流:了解智能体如何自主检索市场趋势、竞争对手情报、内部数据,并整合成策略建议。
- 理解工具集成与记忆机制:掌握循环交互中状态与记忆的重要性,避免“原地打转”。
- 应对故障与自我纠错:学习模型如何迭代重试、调用诊断工具,必要时请求人工介入。
- 明确智能体边界:认识 Agentic RAG 的能力范围,理解它仍受制于既有工具、数据与守护策略。
- 评估价值与场景:判断在哪些业务场景使用 Agentic RAG 能带来切实收益。
- 关注治理与透明度:了解如何通过可解释性、偏差控制与人工审查来增强信任。
什么是 Agentic RAG?
Agentic RAG 指的是一种让 LLM 同时具备“外部检索能力”和“自主决策能力”的生成范式。系统不会只执行一次检索,而是以循环方式调用模型:模型基于当前进展,选择或调整要调用的工具(向量检索、SQL、第三方 API 等),评估结果,再决定下一步操作。借助这种“制造者—检查者(maker-checker)”式的自检流程,系统能更好地修复格式错误的查询、提升回答正确率,并输出更高质量的结论。
Agentic RAG 的正式定义
与传统通过模板提示链驱动的 RAG 不同,Agentic RAG 强调 LLM 的自主规划能力。每一次模型调用之后,系统都会评估当下的结果,决定是否需要重新组织查询、追加其他工具,或继续深化推理。这个循环会持续,直到模型判定答案足够完善。
下图展示了核心循环:
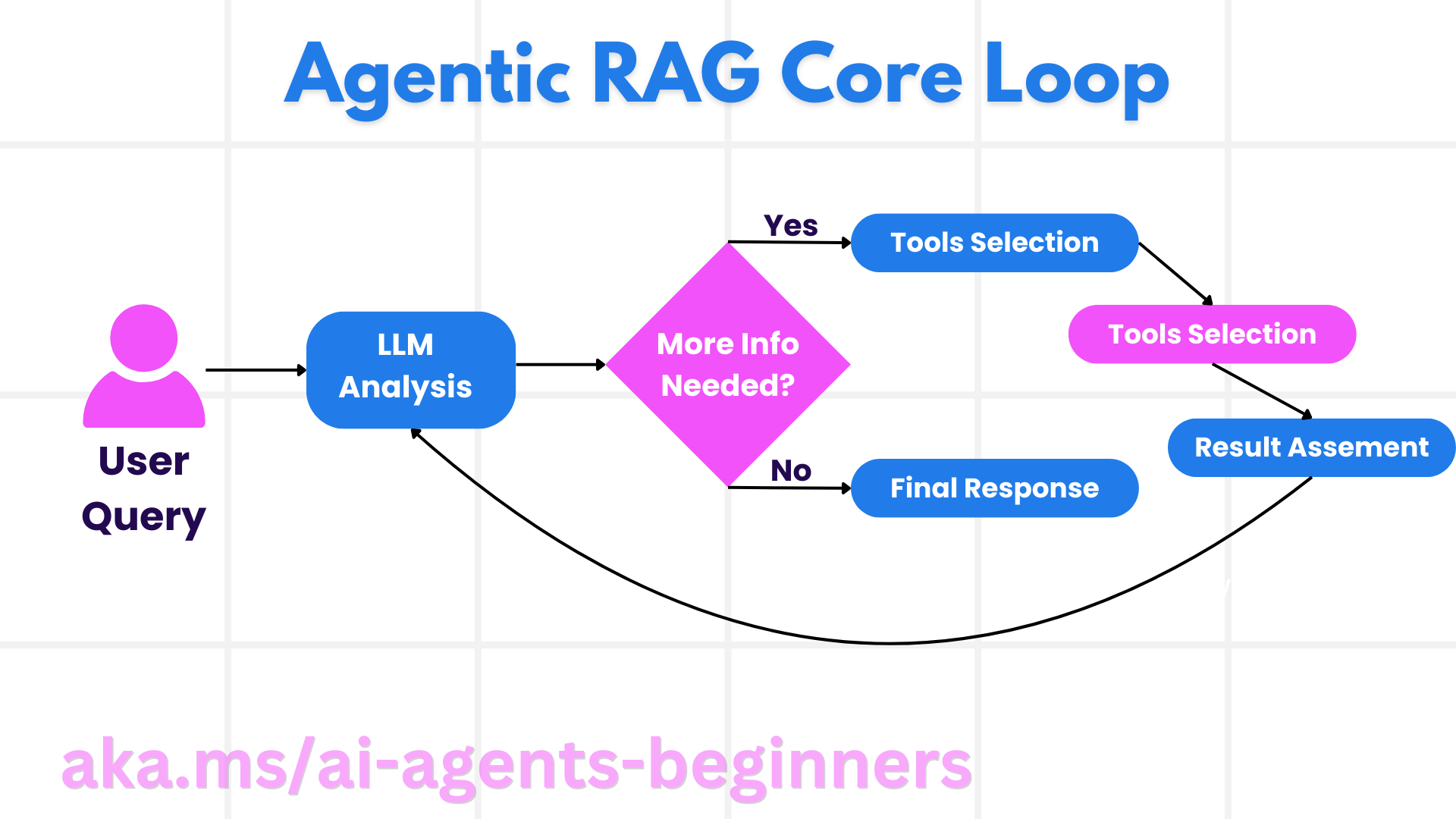
掌控推理过程
“Agentic” 的关键在于系统可以自己掌控推理流程。传统 RAG 往往需要人为设计一条固定的思路(例如详细的 Chain-of-Thought),告诉模型先做什么、再做什么。而在 Agentic RAG 中,模型会依据数据质量自主安排步骤,而不是执行脚本。
以“制定新品发布策略”为例,智能体不会仅仅遵循写死的提示词,而是会自行判断:
- 通过 Bing Web Grounding 获取最新市场趋势报告;
- 利用 Azure AI Search 检索竞争对手信息;
- 从 Azure SQL Database 提取历史销售数据并交叉验证;
- 借助 Azure OpenAI Service 对信息进行整理与综合;
- 检查策略是否存在遗漏或矛盾,必要时再发起新一轮检索。
整个过程中的查询重写、数据源选择与迭代尝试,都是模型基于当前结果自主决定的。
循环、工具集成与记忆
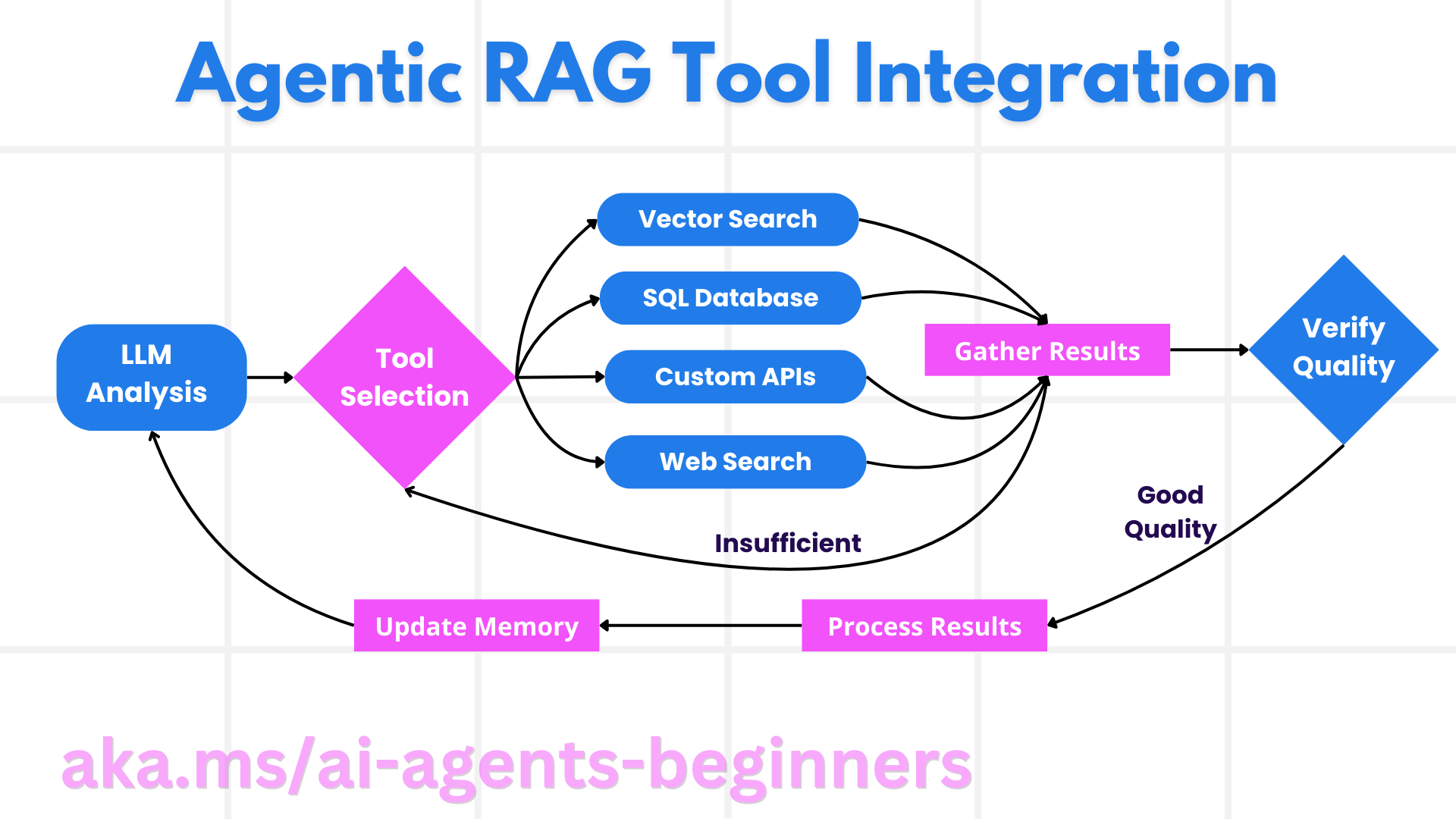
Agentic 系统依赖一个循环式的交互模式:
- 初次调用:用户目标(即提示)交给 LLM。
- 工具调用:若模型发现信息不足或指令含混,则选择工具或检索途径,例如对私有数据执行混合向量检索、调用 SQL 接口等。
- 评估与调整:模型审阅返回结果,判断是否足够。如果不满足需求,就改写查询、换用其他工具或调整策略。
- 循环直至满意:上述流程会不断重复,直到模型确信已收集到充足证据,可以给出最终回答。
- 记忆与状态:系统会跨步骤保留上下文与状态,记录尝试过的方法与结果,避免陷入重复循环。
得益于记忆机制,模型能在长流程中持续积累“对问题的理解”,无需人类频繁干预。
故障处理与自我纠错
Agentic RAG 的自主性也意味着它需要具备完善的自我纠错手段。当系统出现死胡同(例如检索到无关文档、SQL 报错等),它可以:
- 迭代重试:不返回低价值回答,而是重写检索、调整 SQL、换一套数据源。
- 调用诊断工具:启用专门的调试函数,审视推理步骤是否正确。Azure AI Tracing 等工具能提供可观测性,帮助定位问题。
- 请求人工介入:在高风险或多次失败的场景,模型可以提示人工审查。人在纠正后,模型会吸收反馈继续执行。
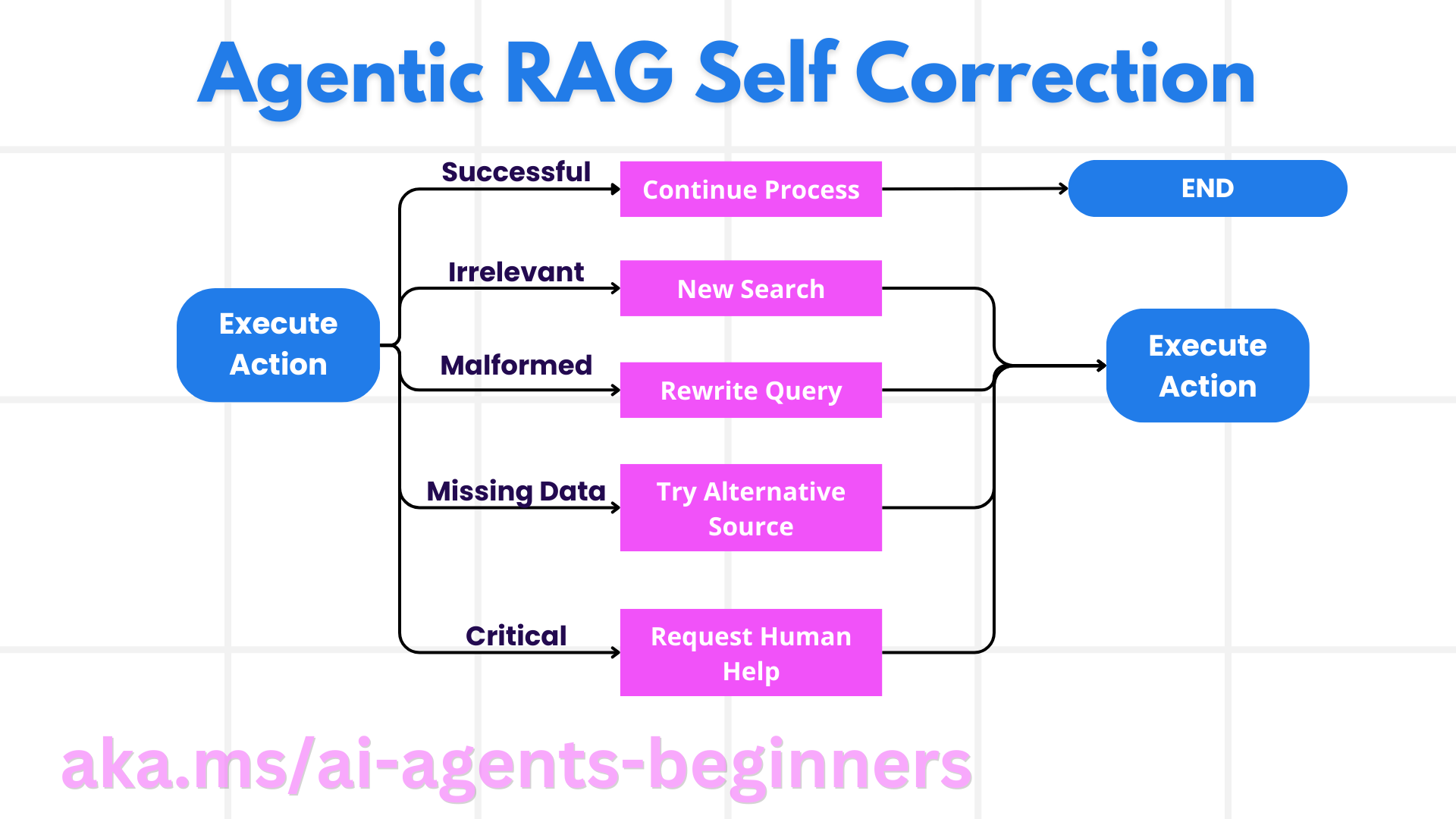
通过这种动态迭代,模型可以在单次会话中持续提升表现,不再是“一次性回答”的工具。
智能体能力的边界
需要强调的是,Agentic RAG 并不等同于通用人工智能。它的自由度始终受限于开发者提供的工具、数据和规则,不会凭空创造资源,也不会突破安全策略。
- 领域内的自主性:系统被设计用于解决特定领域的问题,会通过重写查询、选择工具等方式改进结果。
- 依赖基础设施:其能力上限取决于集成的工具与数据。若想扩展能力,仍需人工改造。
- 遵循守护策略:伦理规范、合规要求、业务策略依旧重要,智能体的行动会被这些安全规则约束。
价值与典型场景
Agentic RAG 在需要迭代优化与严谨输出的场景表现尤佳:
- 强调正确性的业务:如合规审查、法规解读、法律检索等,智能体会多次验证事实、对比多个来源,直到答案可靠。
- 复杂数据库交互:面对易出错的结构化查询时,系统可自动修正 SQL,确保检索结果与用户意图一致。
- 长流程任务:在信息不断更新的长周期任务中,模型会持续吸收新数据、调整策略,保持结果有效性。
治理、透明度与信任
当系统具备更强的自主决策能力,治理与可解释性就尤为关键:
- 可解释推理:需要记录检索过的来源、使用过的工具以及推理步骤。Azure AI Content Safety、Azure AI Tracing、GenAIOps 等方案可以提供辅助。
- 偏差控制与均衡检索:开发者应配置检索策略,确保覆盖代表性数据源,并通过审计来发现偏差。
- 人工监督与合规:在敏感任务中,人工复核仍不可或缺。Agentic RAG 的目标是增强人的判断,而不是取而代之。
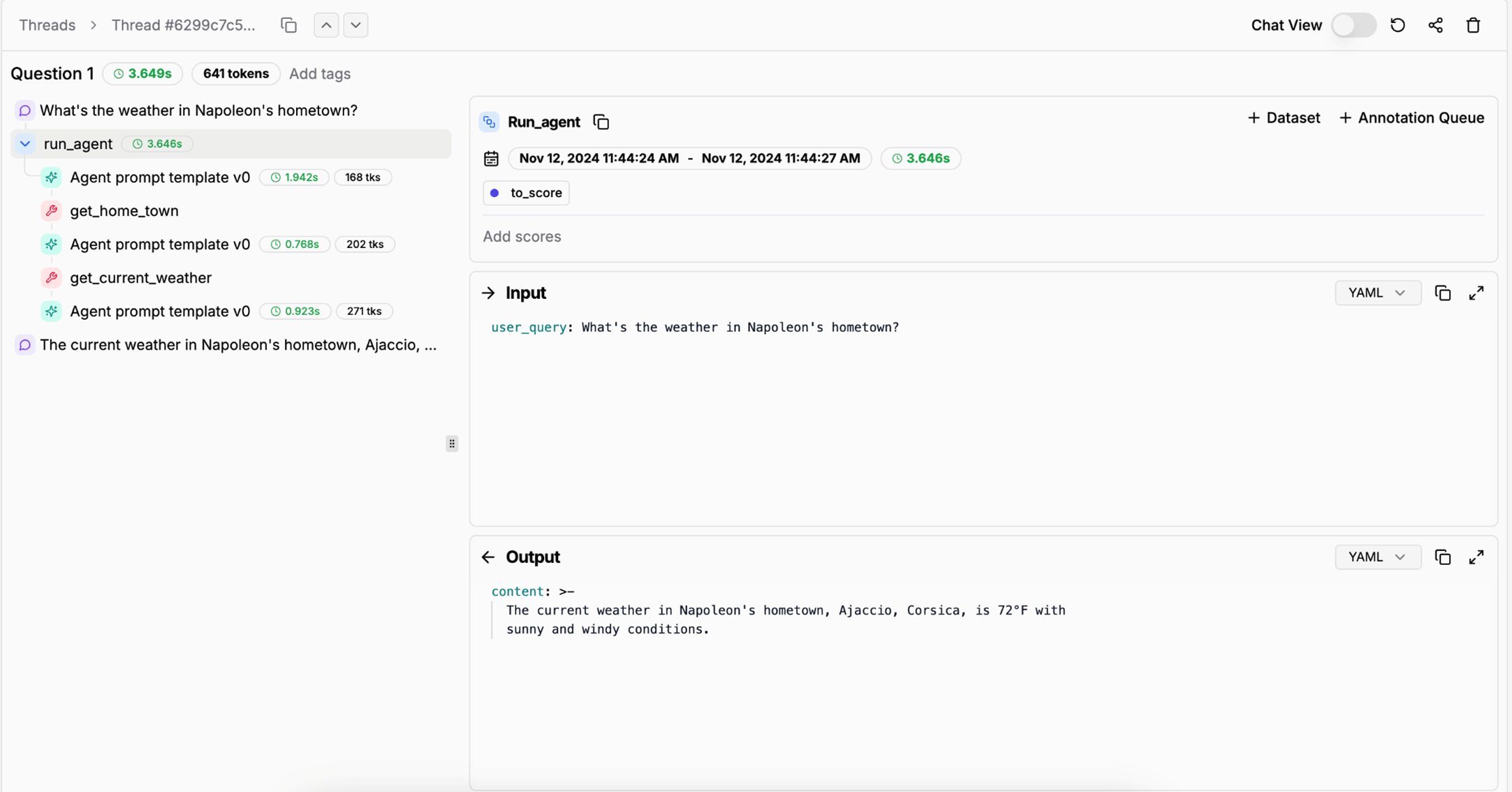
具备清晰的行动记录至关重要。否则,排查多步骤流程的错误会十分困难。如下图所示(来自 Literal AI / Chainlit 的示例),完整的 Agent Run 记录能够帮助快速定位问题:
小结
Agentic RAG 体现了 AI 系统在复杂数据任务中的自然演进:通过循环式互动、自主选择工具并持续迭代,模型不再只遵循固定提示,而是成为具备上下文感知能力的决策者。尽管它依旧受限于人类设定的基础设施与安全规则,但这种智能体能力能显著提升企业与用户的交互体验。
常见问题交流
如需进一步交流,欢迎加入 Azure AI Foundry Discord,参与问答或办公时间活动。
延伸资源
视频与演讲
- The Future of Knowledge Assistants: Jerry Liu
- How to Build Agentic RAG Systems
- Using Azure AI Foundry Agent Service to scale your AI agents